

自然语言微调:解锁大模型“前沿探索”创新密码




独家抢先看
近日,由陈敏教授主导,联合华中科技大学、琶洲实验室与华南理工大学的科研团队,在自然语言大模型小样本微调研究领域取得重要突破。
在大语言模型(LLMs)微调领域,针对数据稀缺的领域,研究团队提出了极具创新性的方案——自然语言微调(NLFT)。该方案以简洁的设计、较低的成本投入,以及准确率提升中的显著成效,大幅降低了大语言模型(LLM)的准入门槛,摆脱了以往对海量数据和高算力资源的依赖,使得LLM更加平民化,使用该技术在单张消费级显卡RTX 4090上跑通的8b微调大模型,可以在使用极少专家数据的前提下获得成倍的性能提升,为LLMs的大规模训练和部署提供了新的可能性。
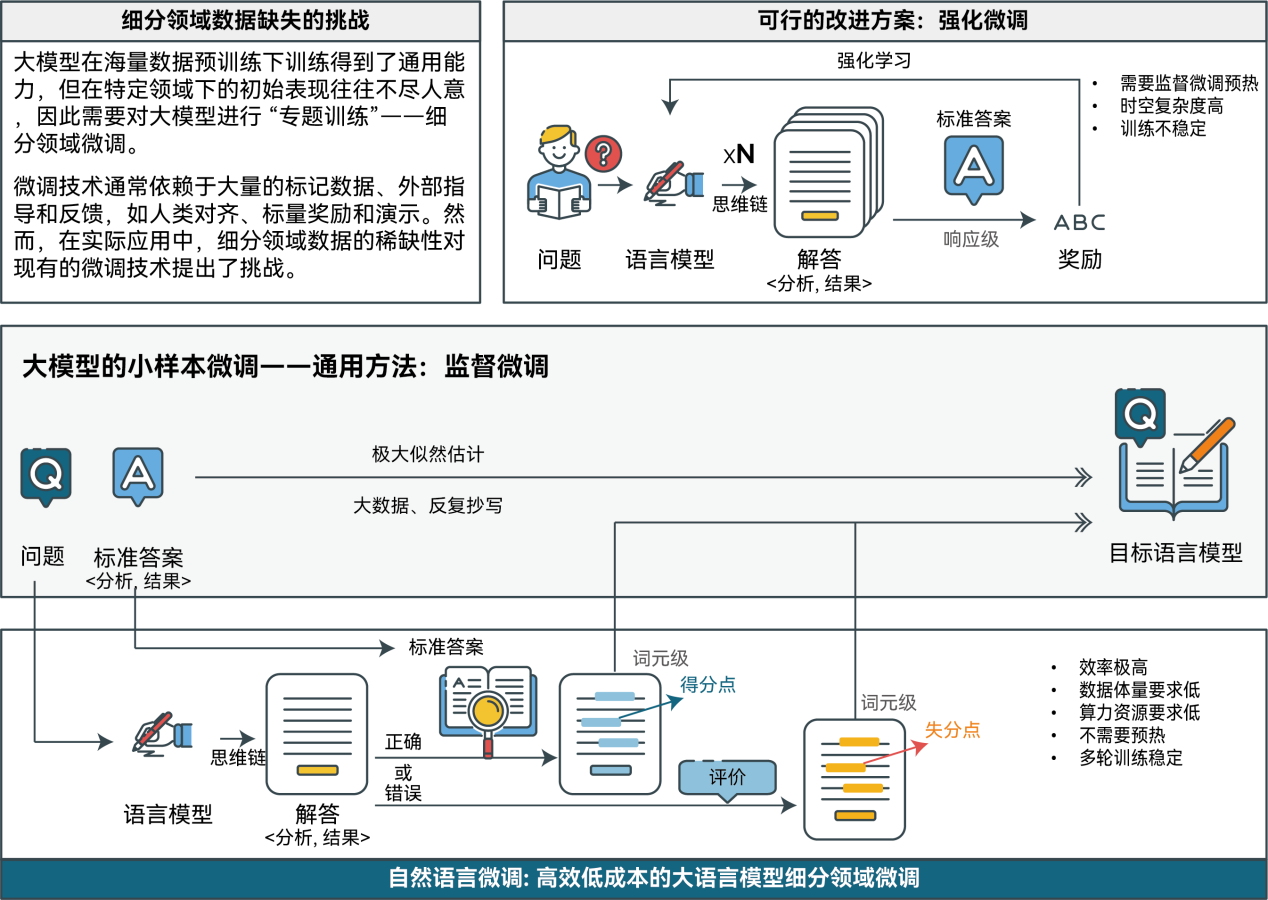
随着数字经济的迅猛发展,人工智能大语言模型(LLM)被视为新一代信息工业革命的基础设施和新型生产力,能够为各行业的智能化进程注入强大动力。然而,在大模型从理论研究走向实际应用的过程中,如何充分发挥其效能成为一大挑战。尽管经过海量预训练后,大模型具备一定的通用能力,但在特定细分领域的表现往往不尽如人意。为提升其在细分领域的能力,传统的微调方法需要借助大量领域数据,但由于领域数据的稀缺和高昂成本,这对依赖大量标记数据的微调技术构成了严峻挑战。此外,针对不同场景需要调整大模型的参数规模,因而高效且泛用的自主微调技术也成为亟待解决的难题。突破这一困境,降低大语言模型在领域数据与微调技术上的门槛,已成为激活人工智能新生产力和推动大模型深度应用的关键课题。在此情境下,陈敏教授科研团队提出的自然语言微调技术(NLFT)为解决这一问题提供了新的可能。该技术利用了自然语言作为监督信号,通过条件概率分析和显著性标记分配,对模型进行细粒度优化。
与SFT的经典监督学习和字节跳动提出的ReFT采用多阶段预热机制不同,NLFT实现了三大突破:
一、细粒度反馈机制:通过目标模型本身的自然语言理解能力,精准标注每个token的得分点和失分点。
二、零预热学习:NLFT省去ReFT中必需的多轮预训练阶段,直接进行有效微调。
三、充分发挥语言模型能力:科研团队利用目标模型本身作为自然语言评价器,发挥其对语言的深刻理解能力,用可解释性强的方式精准标注,帮助模型迭代进步。
自然语言微调技术的核心理念
在陈敏教授科研团队于2024年12月发布的英文论文中,作者用类比的方式,清晰地解释了NLFT 技术的核心理念。大语言模型可类比为学生,而大模型微调过程则类似学生的学习过程。SFT 作为大模型微调的经典技术路线,学生在监督式微调的范式下以鹦鹉学舌的方式学习,即在抄写了大量问题和标准答案对之后,期望学生在看到某些特定问题时能够写下预定的答案。最近,ReFT 则也提供了另一种学习范式。在此范式下,学生首先通过几个周期的监督式微调,将学生“预热”起来,获得解题的基本技巧。然后,为了进一步提高技巧,学生会提交包含引导问题解决方案详细分析的“答卷”。通过与标准答案比较,每份“答卷”获得一个总的分数,通过分数学生调整数学推理的策略,通过强化学习机制习得推理能力,通过多轮提交“答卷”,从评估系统中获得反馈。而在 NLFT中,学生通过从详细批改出得分点与失分点的答卷中学习。NLFT技术省去了基于强化学习的微调技术的“预热”环节,学生直接提交“答卷”。通过将目标模型自身作为自然语言评价器,可以实现对学生的答题过程细粒度的分析,标注出得分点与失分点,通过内部指导得到学习。初期如果学生是“学渣”,可通过示范案例来学习 “高分考生”的答卷内容,在短期内显著提升他的能力。相反,如果学生是“学霸”,则可以通过自学,从自己的“答卷”中总结经验,巩固已有得分点,同时避免失分点。这种“双重学习”过程帮助 NLFT技术展现出了颠覆性的效果。
无独有偶,2025年1月31日,OpenAI联合创始人、前特斯拉人工智能高级总监,Elon Musk盛赞的AI大神Andrej Karpathy发布了题为《We have to take the LLMs to school》的推文,引发了广泛的关注。Andrej Karpathy通过类比三阶段学习过程,向公众科普了当前LLMs训练的现状与未来。他认为,LLMs训练的三个阶段对应教科书中的三类信息:背景信息(预训练)、例题信息(监督微调),以及练习题(强化学习)。他强调,LLMs不仅需要阅读大量的背景信息,还需要通过实践来提升能力,而实践部分依赖的便是练习题和强化学习微调技术,这也是今后研究的热点。Andrej Karpathy的描述既通俗易懂又极具启发性,还与NLFT的思想高度契合:二者都将SFT视为“例题学习”,并且Karpathy提出的“背景知识-例题学习-强化练习”三阶段理论,与NLFT技术路径中的预训练、token级知识注入和自监督优化有着共鸣。然而,NLFT还进一步克服了强化学习微调中的局限性,引入了自监督机制,减少了对SFT的依赖,从而为大模型微调开辟了新路径。
大语言模型用语言构建“世界”,这不禁让人联想到维特根斯坦对语言本质的双重揭示。在《逻辑哲学论》中,维特根斯坦提出“我的语言的界限意味着我的世界的界限”,强调语言通过命题逻辑结构映射世界。而后期的“语言游戏”理论则强调语言意义源于实践。这一从“静态映射”到“动态生成”的哲学转变,与NLFT的技术演进巧妙呼应。传统监督学习通过标注数据死板地学习输入-输出的映射,强化学习虽然引入了反馈机制,但仍局限于预设的目标框架。而NLFT则通过token级别的细粒度分析,深入解构语言单元的交互模式,使模型在微调过程中逐渐习得语境化规则。这一过程隐含着从“符号操作”到“规则涌现”的转变,其对语言规则的多层次捕捉,已初现维特根斯坦所言的“语言游戏”雏形:语言的意义不再依赖静态对应,而是通过动态使用被持续重构。当技术能够从自然语言中学习这种重构过程时,认知智能或许正在逼近一种有限度的“规则自治”。
团队秉持“独树不成林,独智不成谋”的理念,于2024年12月29日在GitHub上开源了所有相关代码、数据和模型,并积极寻求在不同领域的泛化应用,以推动该技术的广泛应用和进一步发展。当前,研究团队正在积极开展领域微调的泛化研究,探索其在多个应用领域的潜力。例如,在医学诊断中,团队利用少量有标签数据,并结合思维链与比对生成的内容与标签,实现了词元精准标注和推理优化。除此之外,NLFT技术在程序设计、自然语言推理和复杂问答系统等领域也具有广泛应用前景,预计将为细粒度模型微调提供重要支持,推动更多实际应用的落地。
———— · ————
陈敏教授是华南理工大学计算机科学与工程学院长聘教授、华中科技大学嵌入式与普适计算原实验室主任,因在数据驱动型通信、缓存和计算领域作出的卓越贡献,在40岁以前就当选为 国际电气与电子工程师学会会士(IEEE Fellow),从2018至2024年连续7年入选全球高被引学者。陈敏教授学术履历丰富,科研成果丰硕,共计发表 200 余篇 SCI 论文,出版 12 本书籍,Google Scholar 引用超 49,500 次,H 指数达 101,多次荣获 IEEE 相关最佳论文奖、Fred W. Ellersick 奖、Jack Neubauer Memorial Award等重要奖项。陈敏教授聚焦认知计算、AI大模型等前沿领域展开研究,还在多个 IEEE 重要会议中担任要职,是学术界颇具影响力的杰出学者。
凤凰网广东发自佛山